我有一些網站頁面不想顯示在搜尋的結果頁面,要如何防止被搜尋引擎索引? -- WA105心得筆記
- 夢龍筆記
- 上層分類: 網路經營
- SEO 搜尋引擎優化
Meta Robots 跟 Robots.txt差別 WA101 4th Meetup 心得筆記
這是篇心得筆記,來源是Web Analytics 101社團的第四次實體聚會:Meta Robots 跟 Robots.txt差別 / 孟令強。
有哪些情形會不希望搜尋引擎爬取這些網頁?
- 未完成、施工中的網站。
- 不重要的頁面。
- 保護資料、不想被搜尋引擎檢索的網頁。
未完成、施工中的網站
有些網站公司在架設編輯的過程是在開放性的網路環境、或者網路主機上作業,這樣子好處是可以遠端共同協作,而且有網址也方便客戶檢視;但是通常會發生一個問題,網站被搜尋引擎先收錄了… 因為重複內容的問題,當網站移交給客戶之後,很長一段時間搜尋引擎的檢索結果都是錯誤的內容、或者是網站公司的臨時網址,影響到客戶網站的搜尋結果和流量;甚至搜尋出一些很詭異、有問題的頁面。
有經驗的公司會在編輯階段鎖住搜尋引擎索引網站,移交之後再開放,避免搜尋結果出現"施工中XXXX"。
不重要的頁面
對於搜尋結果不是很重要的頁面,或者一些集合性質的頁面,通常會鎖住避免搜尋引擎檢索,如About me關於我、或者公司簡介這種不是很重要的頁面如果沒有鎖住搜尋引擎爬取,會消耗搜尋引擎的爬率,每個網站能分配的檢索資源是有限的,當爬率消耗在這些不重要的頁面,就會影響重要、想要有SEO成績的網頁被索引的量,以及出現的時間點。而集合性質的網頁如站內搜尋的結果頁、或者Tag標籤的頁面,是集合站內類似性質的網頁而成,有可能會製造站內重複內容的問題,所以也需要阻擋搜尋引擎索引。
保護性質,不想被索引的頁面
也許有些頁面資訊雖然開放在網站上,但是不想讓人在SERP (搜尋引擎結果頁),上就直接看到內容,希望使用者一定要進站看資訊;或者是一些比賽的成績、施政報告等不得不公開、卻又不想讓人看到的資料,同樣也不想輕易讓人搜尋引擎找到、翻閱。而之前也發生過某個雲端PDF轉檔工具網站被Google爬進去,一堆公司的報價單、合約書、契約書等都被搜尋引擎蜘蛛索引,強制曝光在網路上。
過去阻止搜尋引擎爬取網頁的方式:robots.txt限制、封鎖蜘蛛的行動
以往要阻擋搜尋引擎爬取網站,多半會在robots.txt裡面下Disallow來告訴搜尋引擎禁止索引哪些內容,但現在Google有公告說robots.txt不能作為隱藏網頁,不讓頁面出現在Google SERP的方式,因為即使robots.txt有設定,但是頁面如果有外部連結,無法阻止googlebot順著外部網頁的連結爬... 爬過來…,所以robots.txt沒用,還是會被Google爬取、索引進伺服器之中。
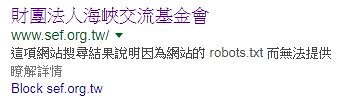
據說這個就是設了robots.txt禁止搜尋引擎的結果
現在有哪些方法可以阻擋搜尋引擎的索引?
Google說明如果要防止Googlebot存取網站的網址,需要使用"noindex"封鎖搜尋索引服務,或者將這個網址從伺服器目錄直接加密封鎖;其他的方法還有CMS系統直接設定,將網站離線,以及孟令強提供從GSC的移除網址暫時將網址從搜尋結果之中移除。
使用「noindex」封鎖搜尋索引服務
Google說明,如果要避免特定網頁出現在 Google 搜尋結果中,必須在該網頁的 HTML 程式碼中加入 noindex 中繼標記,或是在 HTTP 要求中傳回「noindex」標頭。這樣一來,當 Googlebot 下次檢索該網頁時,就會發現「noindex」標記或標頭,進而將其完全排除在 Google 搜尋結果之外,不論是否有其他網站連結到該網頁皆是如此。
重要事項:該網頁不能遭到 robots.txt 檔案封鎖,否則 noindex 中繼標記就無法生效。如果網頁遭到 robots.txt 檔案封鎖,檢索器便無從發現 noindex 標記;舉例來說,如果有其他網頁連結到該網頁,該網頁將繼續顯示在搜尋結果中。
透過受密碼保護的伺服器目錄來封鎖網址
如果從伺服器直接封鎖、將網頁目錄加密鎖定(如Apache的.htaccess),任何搜尋引擎包括Google都不可能索引得了這個網頁,別說搜尋引擎拉,連到就要先敲密碼才能進入,看都不能看了。只有知道這個目錄密碼的人才能瀏覽這個頁面。
使用GSC的移除網址功能
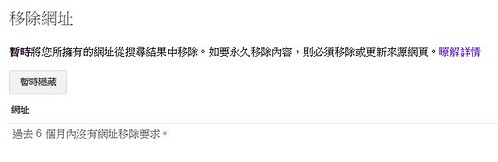
孟令強老師說可以使用GSC(Google Search Console 網站管理員)的移除網址功能,可以暫時禁止Googlebot爬取這個網址,最長有效時間為90天,相信這個時間對一般網站架設公司來說應該很夠用了。
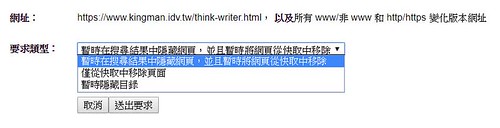
GSC 網址移除設定畫面
使用CMS系統設定暫時關閉網站
如果使用CMS系統架設網站,部份系統就有提供暫時關閉網站的功能,如Joomla!就可以在後台設定將網站離線,前台就必需要輸入具備相對映等級權限的帳號以及密碼才能登入網站前台、瀏覽網站。
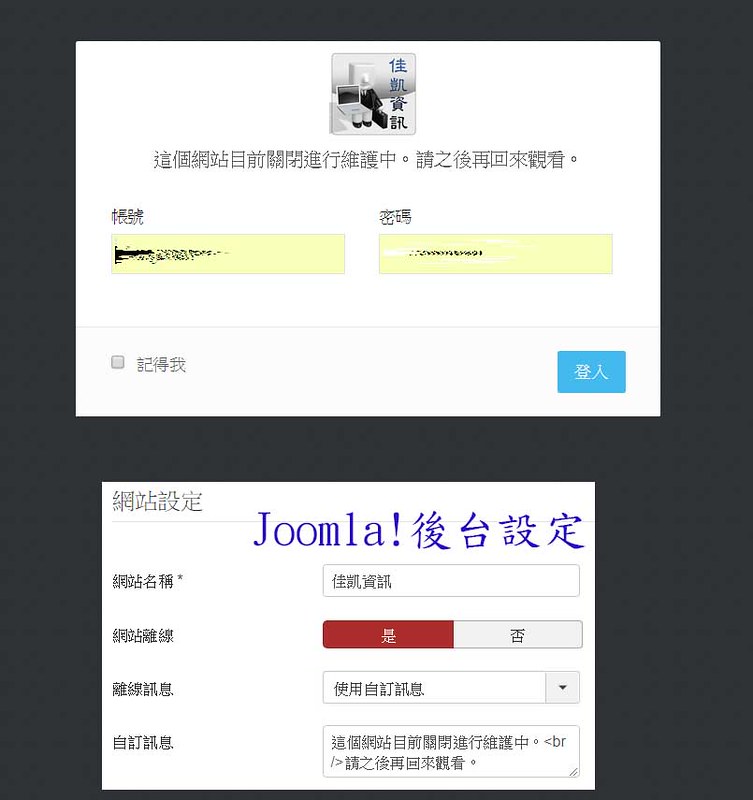
Joomla!系統後台設定網站離線,前台就必需要登入帳號密碼才能瀏覽網站
如果我的網站都不建立外部連結、也不提交XML Sitemap給GSC,可以避免網頁被Google索引嗎?
也許有人會想,如果我不在GSC提交XML Sitemap給Google,Google搜尋引擎就不會知道有這個網站的存在,而我也不建立外部連結,沒有其它網頁將連結指向這個網站,沒有連結,Googlebot沒有管道爬過來,這樣子應該就不會被搜尋引擎知道、索引了吧?
依據孟令強老師演講的內容所說,國外有人做過實驗,大約在第23天左右Google搜尋引擎仍然爬到了這個網站…
番外:香港公司販售的佈景主題(Theme、Template)很多預設會封鎖中國的搜尋引擎
另外孟令強老師特別提醒,如果網站對口中國,想被中國的搜尋引擎如百度、搜狐等收錄、想做中國區的SEO,要特別注意香港的Theme佈景主題。依處理經驗發現來自香港的佈景主題會特別封鎖中國的搜尋引擎,禁止這些搜尋引擎爬取網站,所以如果使用香港的佈景主題,又需要經營中國區的SEO,要特別檢查佈景主題檔案,移除這些禁止索引的設定。

謝謝各位講者的分享,謝謝Web Analytics 101社團提供這麼好的分享聚會,我絕對不會承認我是哪一隻的;後面會陸續將我聽得懂得筆記分享出來。
- 點擊數: 25839




